# 项目数据管理设置
创建一个项目时,通常需要先在项目管理设置中添加可用的数据源、设置项目的默认数据库,除此之外,还可以在这里设置模型与物理表之间描述信息的同步策略、执行查询时NULL值的排序规则等。主要分为数据源、模型、权限、查询、性能优化五个方面的设置。
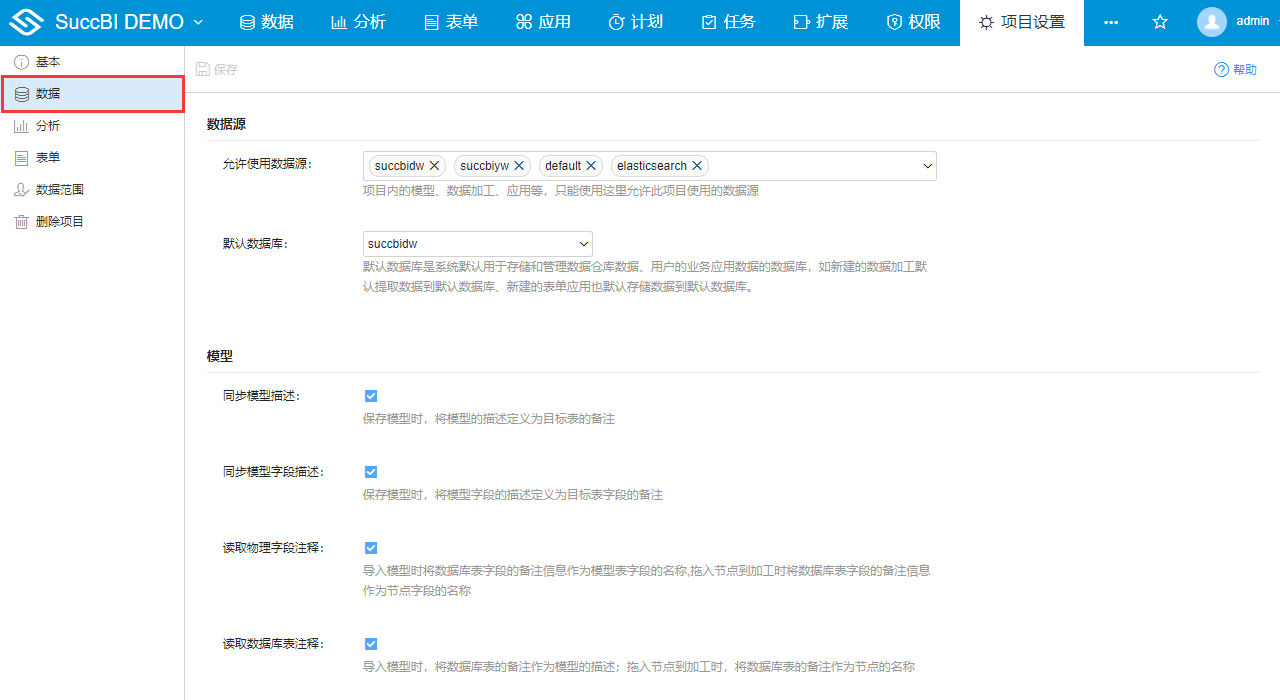
# 数据源
# 允许使用数据源
添加允许在项目内部使用的数据源,项目内的模型、数据加工、应用等,只能使用此处添加的数据源。创建项目时默认只有default数据源,如果需要接入新的数据源,可通过以下两种方式添加:
# 默认数据库
默认数据库是系统默认用于存储和管理数据仓库数据、用户业务应用数据的数据库。新建的数据加工、表单应用中的数据默认存储到默认数据库。
TIP
只有可写的数据源才能作为默认数据源,可在数据库连接属性中进行设置。
# 默认Elasticsearch数据源
默认Elasticsearch数据源作为新建Elasticsearch模型时的默认存储库。该选项只能指定Elasticsearch类型的数据源,设置后,新建Elasticsearch模型后方便保存时自动生成索引。
# 模型
# 同步模型描述
默认勾选,保存模型时将模型描述定义为目标数据库表的备注。
模型的描述通常作为模型的业务解释,若全部同步到数据库表上,其他直连数据库的人也能看到,可能会导致项目模型的业务设计泄露。如果项目对业务设计的安全性要求较高,可以取消勾选。
# 同步模型字段描述
默认勾选,保存模型时将模型字段的描述作为目标数据库表字段的备注。
模型字段的描述通常是模型字段的业务解释,若全部同步到数据库表字段上,其他直连数据库的人也可以看到,这样会导致项目模型的业务设计泄露。若项目对业务设计的安全性要求较高,可以取消勾选。
# 读取物理字段注释
默认勾选,导入模型时将数据库表字段的备注信息作为模型表字段的名称,数据库表作为节点拖入到加工时,数据库表字段的备注信息会作为节点字段的名称。
使用SuccBI建模时,自动读取物理字段注释,能很好地帮助使用者理解模型的结构和数据。通常是需要勾选的,但是有些数据库读取数据库表的元数据信息很慢,比如vertica,为了避免影响使用时的性能,可以取消勾选。
# 读取数据库表注释
默认勾选,导入模型时将数据库表的备注信息作为模型表的名称,数据库表作为节点拖入到加工时,数据库表的备注会作为节点的名称。
使用SuccBI建模时,自动读取数据库表注释,能很好地帮助使用者理解模型的用途。若在项目中使用的数据库读取数据库表的元数据信息很慢,比如vertica,为了避免影响使用时的性能,可以取消勾选。
# 隐藏字段属性列
选择需要隐藏的字段属性,在项目内的模型中查看字段列表时,勾选的字段属性不会显示。
项目会默认显示所有的字段属性,在模型的字段列表中显示时比较冗余,列宽容易挤压,可以根据项目建设的用途隐藏掉不常用的字段属性,简化字段列表的显示。比如在业务系统的建设中,通常不需要数据元、取数公式、取数条件等数据治理项目常用的属性,可在此处将属性列隐藏。
# 记录实时查询总行数
勾选后,项目创建或保存实时查询的数据加工时会在数据表信息表中记录加工总行数,不勾选只会记录落地数据加工的总行数。默认是不勾选的,若项目希望通过数据表信息表中记录的数据在前端展示数据模型的总行数,可以勾选此项。
# 权限
# 启用“我的数据”
默认不启用,启用后,会在数据>模型中增加我的模型目录,用户可在我的模型中管理自己的私有数据和数据模型。
在一些企业或机构中,有些业务人员也需要独立地进行数据处理和分析,他们创建的模型是私有的或临时的,不应该存放在企业级的公共数据仓库中,比如税务部门下的税务人员也会自助分析偷漏税企业的情况,这种场景下就可以启用我的数据来管理自己的私有模型和数据。
# 启用“应用数据”
默认勾选,勾选后,会在数据>模型中增加应用模型目录,用户可在应用模型中管理表单应用和应用模块产生的数据。
表单应用或应用模块录入的数据,有一些是项目的业务数据,若项目对业务数据的安全性要求较高,不希望用户在数据模块中查看这些数据,如核酸检测的录入信息,可以取消勾选。
# 允许访问系统数据
默认不勾选,勾选后,会在数据>模型中增加系统数据目录,用户可在系统数据中查看日志数据、用户数据等系统数据。
为了保证系统的正常运行,防止用户修改系统数据后系统运行故障,通常此项是不勾选的,若用户希望在项目中对日志数据、用户数据等系统数据进行加工,通过加工后的数据在项目中展示当前系统运行情况,可以勾选此项。
# 允许上传数据文件
默认勾选,勾选允许上传数据文件后,会在数据>数据源>文件数据源中增加上传数据文件选项,用户可点击此项从本地上传数据文件到系统进行数据加工。若需要上传的文件较大,可在系统设置>安全设置>阈值设置>文件上传设置上传文件大小阈值。
一些项目出于对数据安全和规范的考虑,只允许用户使用项目内的数据进行数据加工,此时可以取消勾选,将上传数据文件选项隐藏,使用户无法上传本地数据到项目中。
# 允许访问公共数据
启用允许访问公共数据后,会在数据>模型增加公共项目目录,用户可通过此目录访问其他公共项目的数据。通常是不启用的,若需要将公共项目的模型复制到当前项目进行加工,或项目的业务流程需要跨项目设置关联关系,可以启用此项。
# 本项目作为公共数据项目
启用后,本项目将作为公共数据项目被已启用允许访问公共数据的项目访问。为了保证项目内数据的独立性,通常是不启用的,若其他项目需要复制本项目的数据模型进行数据加工,或项目的业务流程需要跨项目设置关联关系,可以启用此项。
# 查询
# NULL值计算规则
默认不勾选,勾选后,当数据为NULL时,会将NULL值当作0值进行处理。
一些数据加工的计算字段中存在很多空值,这样会导致数据加工中大部分行没有结果,为了使加工结果正常返回,需要将字段中的NULL值转换为0值,此时可以进行勾选来实现0值的转换,使加工正常完成。
# 分母为0计算规则
默认勾选,勾选分母为0计算规则后,当存在分母为0的数据时,会将数据当做NULL值进行处理。
# NULL值升序排序规则
对模型数据进行升序排列时,值为null的数据的排序规则,可设置为排在最前、排在最后或数据库默认规则,默认排在最前。
# NULL值降序排序规则
对模型数据进行降序排列时,值为null的数据的排序规则,可设置为排在最前、排在最后或数据库默认规则,默认排在最后。
# Oracle并行查询
Oracle数据源执行查询的并行数,未设置时默认为1,即不启用并行查询。若项目将Oracle中的数据用于多维分析,可在这里设置并行数以提高计算效率。
# Oracle是否使用join语法
默认勾选,勾选后,Oracle数据库表进行关联时使用join语法连接,不勾选则使用(+)语法连接。通常使用join语法进行连接,当Oracle进行多表关联时,若字段数超过1000,建议取消勾选,使用(+)语法进行连接以获得更好的性能。
# 性能优化
# 默认查询预览数据
默认勾选,勾选后,数据加工预览数据时只查询预览数据默认行数中指定行数的数据,以加快预览速度。
项目中数据加工里数据的数据量一般较大,预览全部数据通常较慢,一般不建议取消勾选,若项目中进行数据加工的数据量较小,且用户需要在预览数据时查看全部数据,可以取消勾选。
# 预览数据默认行数
启用默认查询预览数据后生效,在数据加工中添加节点时,新节点预览数据的预览行数,默认预览10000行。