# 索引管理
索引管理是指在模型的性能优化 > 索引中创建并管理其对应数据库表的索引。当模型的数据量较大,而查询的结果集很小时(数据量一般小于原表10%),通常可以根据查询的过滤条件创建数据库索引优化性能。
提示
索引管理是基于数据库索引机制的优化策略,通常用于传统的关系型数据库,如MySQL、Oracle,而对于分析的列式数据库(如vertica)、NoSQL(Mongodb、Elasticsearch)数据库等则没有索引的概念。
# 新建索引
在企业信息自助查询 (opens new window)中,常需要通过【统一社会信用代码】来从企业基本信息表中查询一户企业,这时可以给【统一社会信用代码】添加索引。
在模型管理的性能优化 > 索引标签页下新建索引,如下:
示例地址:企业基本信息表 (opens new window)
- 在
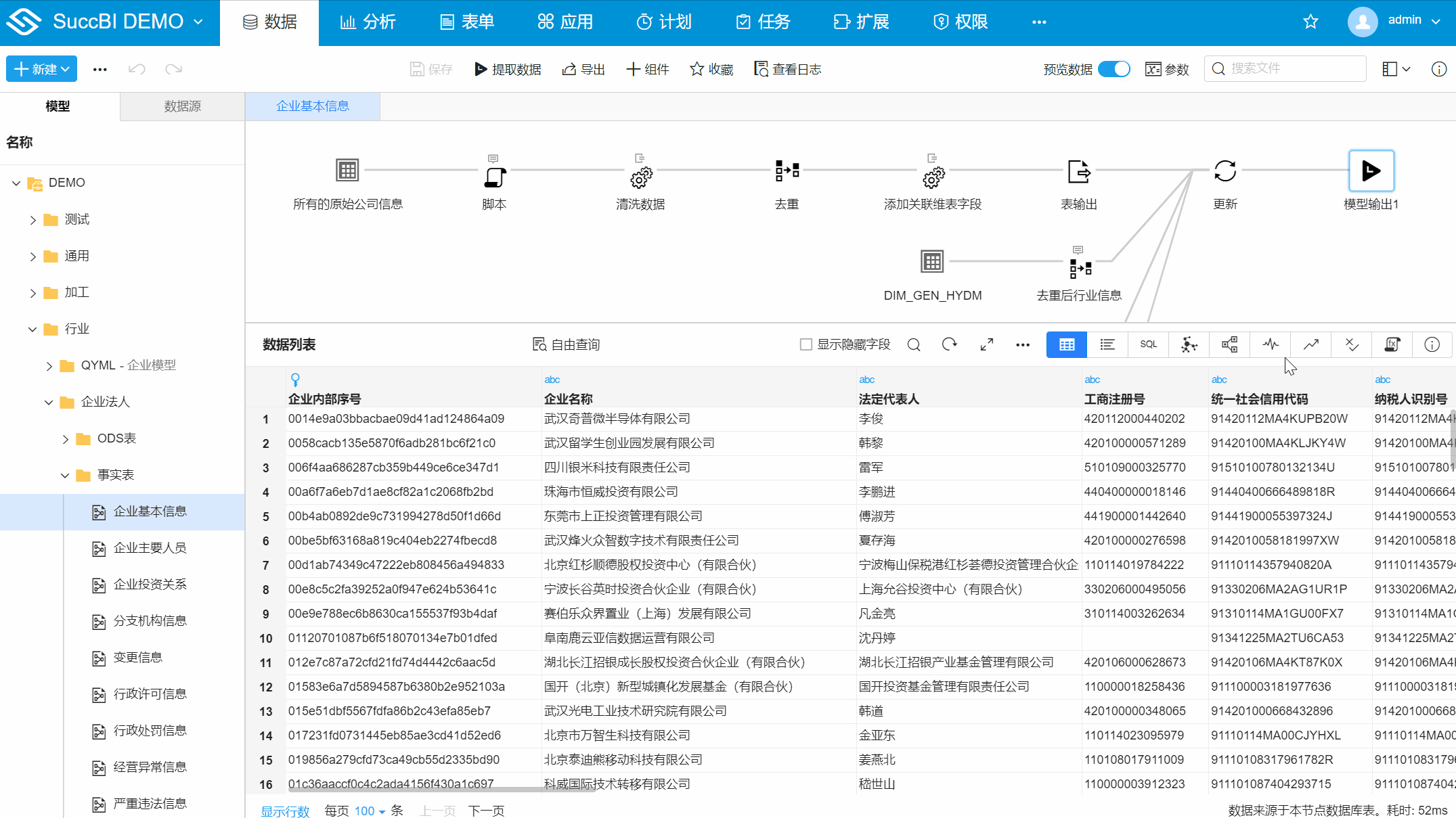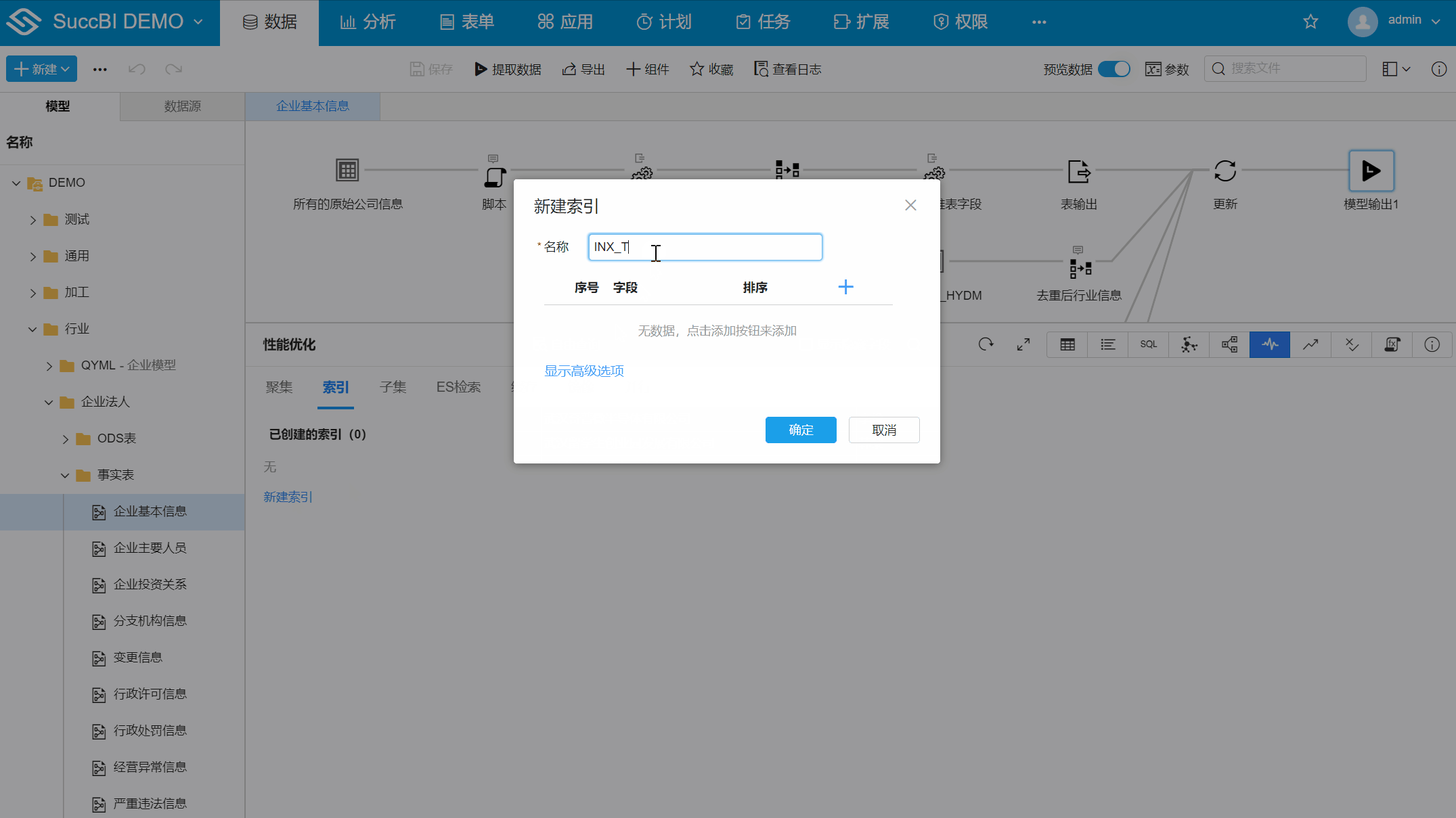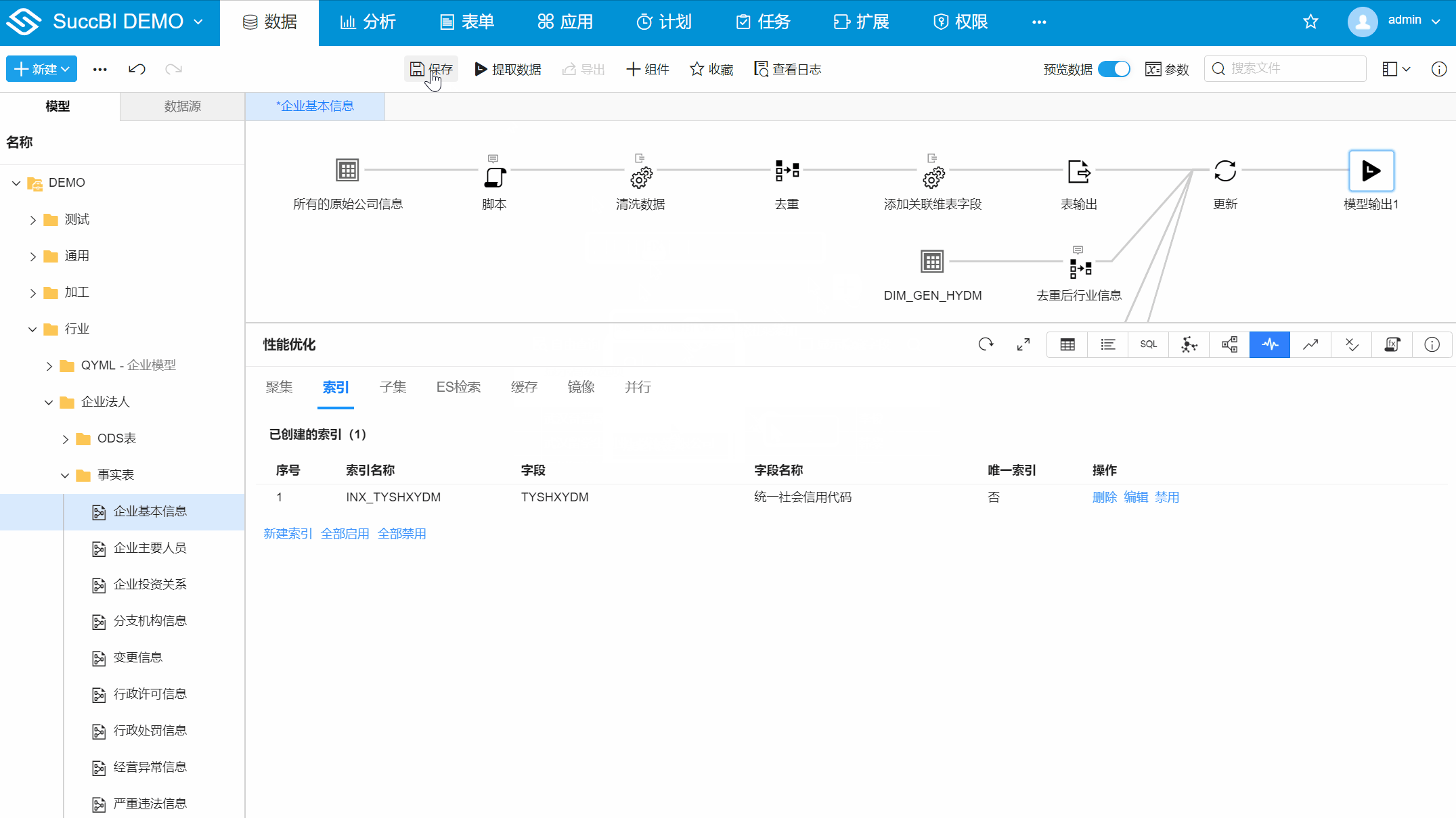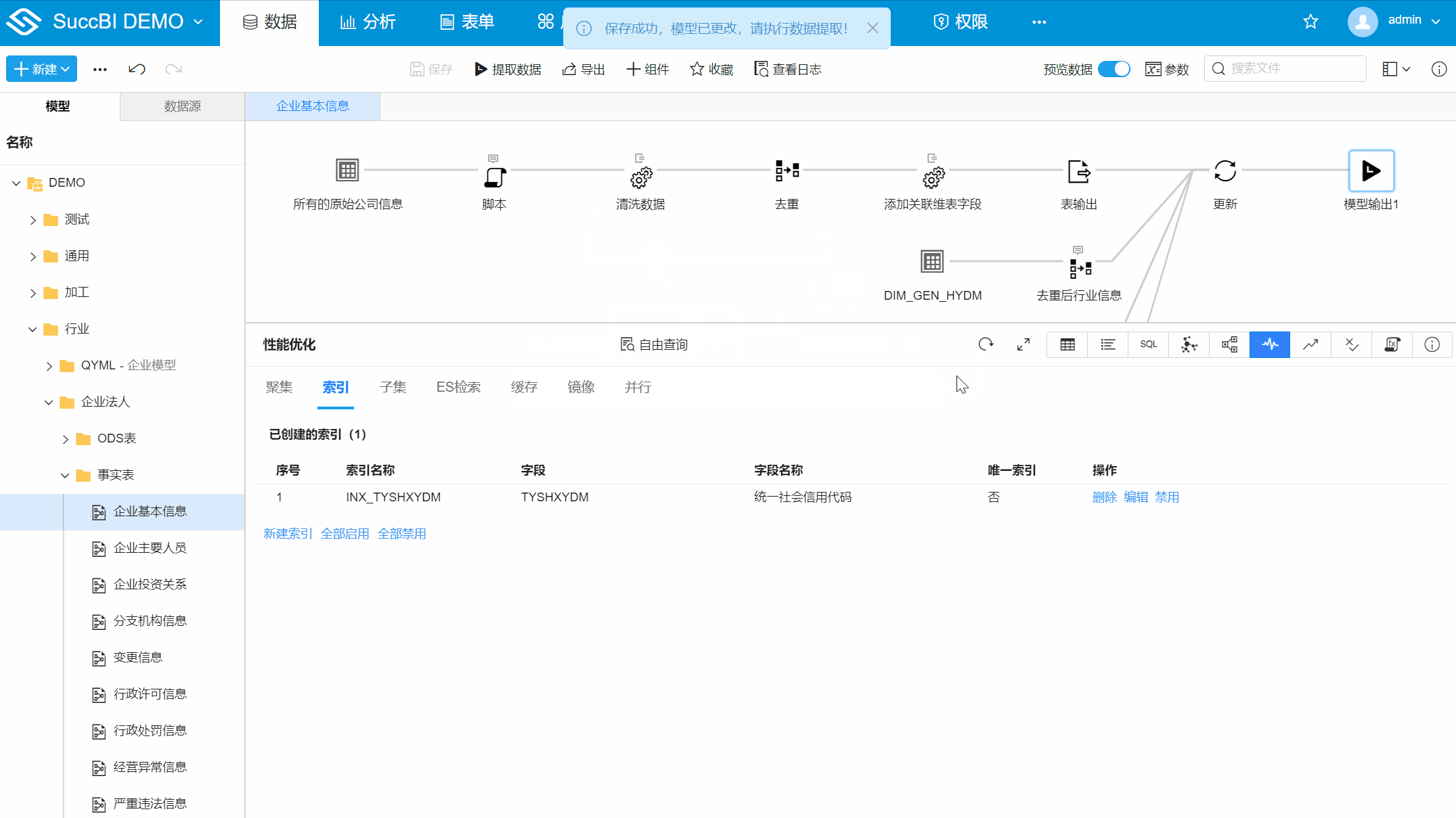
企业基本信息表中切换至性能优化 > 索引 - 新建索引:点击新建索引,弹出对话框
- 名称:输入名称
INX_TYSHXYDM - 添加字段:点击
+,选择字段【统一社会信用代码】 - 保存:点击确定后,再点击模型的保存按钮
# 索引列表
# 索引列表属性
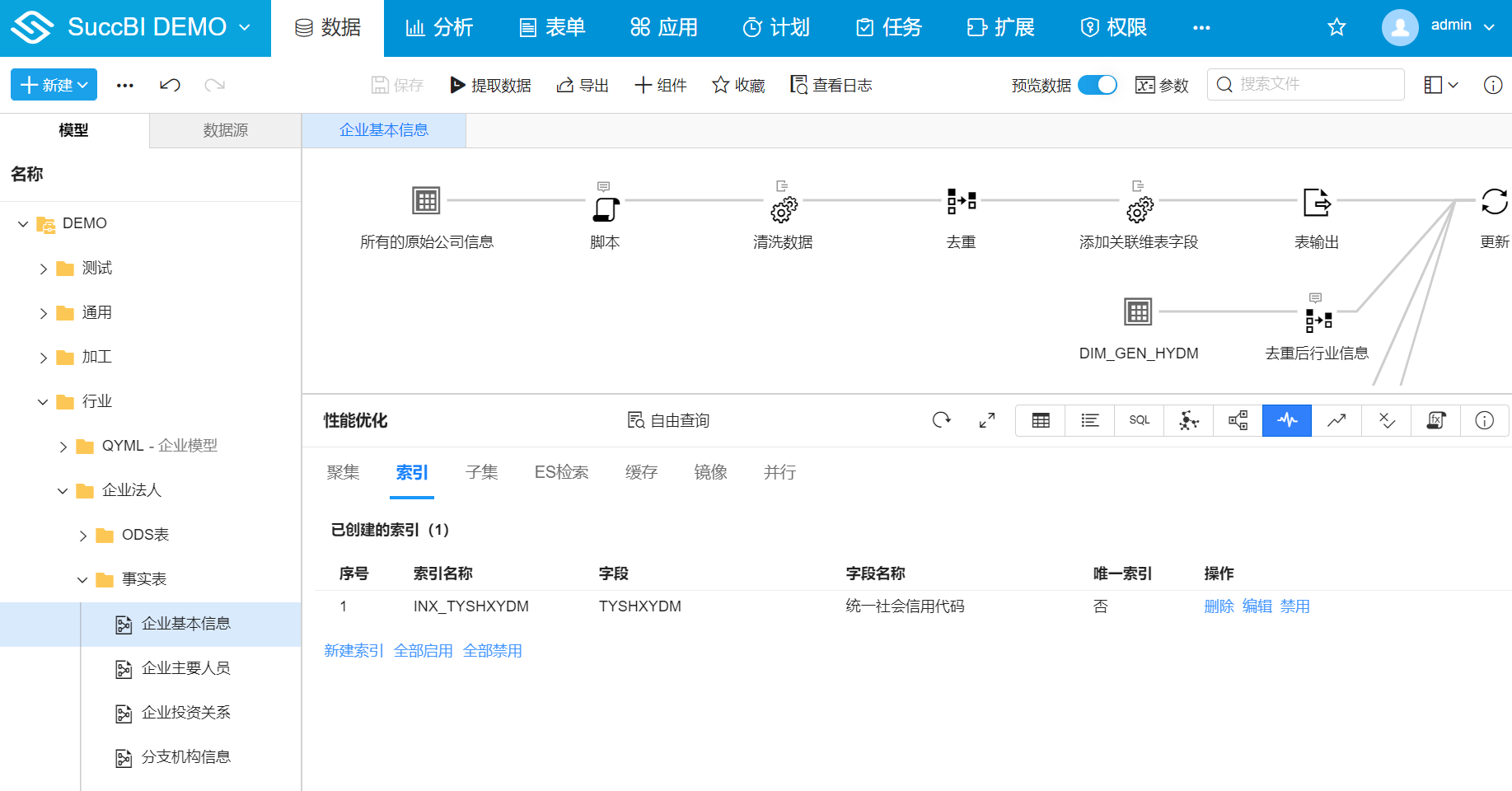
索引列表展示已经创建的索引的信息,具体属性如下:
- 索引名称:创建索引时设置的名称
- 字段:创建索引时选择的字段的物理字段名列表
- 字段名称:创建索引时选择的字段的名称列表
- 唯一索引:创建索引时勾选了高级选项下的作为唯一索引后显示是,否则显示否
- 操作:
# 启用和禁用索引
可以单个或批量启用和禁用索引:
- 单个启用/禁用:在索引列表的操作列中点击启用/禁用按钮来控制对应的索引可用状态
- 批量启用/禁用:在索引列表的下方点击全部启用/全部禁用按钮来批量控制索引的可用状态
提示
# 索引对话框属性
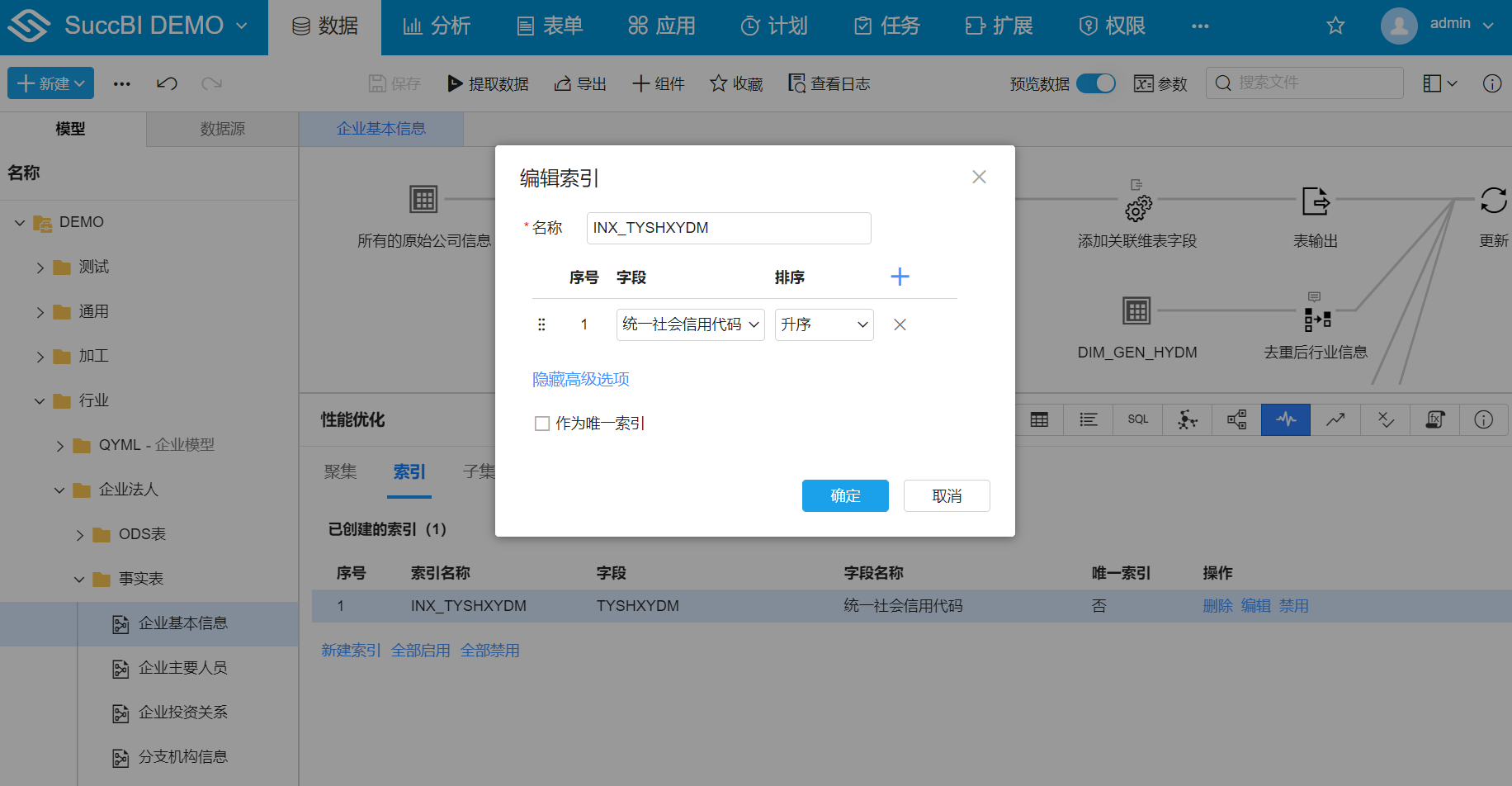
- 名称:索引在模型元数据中的存储的逻辑名称,创建在数据库物理表上的真实索引名是系统自动生成的
- 字段:从当前模型的字段列表中选择
- 排序:默认为升序,绝大部分索引都是升序的,仅当需要模型按照某个字段进行倒序排序时才可能需要创建倒序索引
- 作为唯一索引:点击显示高级选项,可选择勾选作为唯一索引,勾选后表示该索引的字段组合在模型的数据中是唯一的
- 移动字段:可以拖动字段前面的滑动图标来调整索引中多个字段的顺序
为什么需要调整字段顺序?
传统关系型数据库均是最左前缀匹配机制,即索引有多个字段时,必须按照字段顺序从左到右匹配。
举个例子,如果在企业基本信息表中创建了索引(登记机关,成立日期),当你执行如下查询时:
[登记机关]='湖北省武汉市工商行政管理局' AND [成立日期]='2020-01-08',可以使用索引 ✔️[登记机关]='湖北省武汉市工商行政管理局',最左前缀匹配,先匹配【登记机关】,可以使用索引 ✔️[成立日期]='2020-01-08',必须先匹配【登记机关】,不可以使用索引 ❌
# 正确的使用索引
实际项目中索引的优化分析比较复杂,但是从中我们总结出了一些通用的经验或规则,能让普通的业务人员也能正确的使用索引。
使用索引的前提条件
只有当查询的数据集是原表的一小部分(通常要10%以下)时,数据库才能使用索引提升性能。
在熟知使用索引的前提条件后,在创建索引时请遵循如下经验规则:
- 对于频繁进行更新的APP模型,索引的个数尽量不要超过5个,否则会影响数据插入和更新事务的性能
- 模型的维键通常需要创建索引,模型的主键数据库会自动创建唯一索引
- A表关联B表,通常需要在B表的关联字段上创建索引
- 索引键的长度越短性能越好,不要在大文本字段上创建索引
- 创建复合索引时,需要将最常用来过滤的字段放在最前面
- 索引应该创建在经常用于过滤且选择性高的字段上
不等于、不包含、不为空等非运算不能使用索引为空、包含、结尾是不能使用索引,开头是可以使用索引- 过滤字段的数据类型与要过滤的值的数据类型不一致时,不能使用索引
- 字段被函数或表达式引用时不能使用索引
提示
部分数据库支持定义函数索引,目前SuccBI的索引管理中暂未支持
是否有帮助?
0条评论
评论