# Elasticsearch模型
在传统数据库(如MySQL、Oracle)中进行检索时通常只能对字段进行简单的模糊匹配(使用LIKE或正则表达式REGEXP_MATCH),不仅检索效率低下而且查询的结果不能根据相关性排序返回,在海量数据的检索场景下更是束手无策。
Elasticsearch模型是指目标数据存储在Elasticsearch引擎中的特殊模型,基于该模型进行查询时,便能借助专业、成熟的Elasticsearch检索引擎轻松实现对海量数据的全文检索,不仅检索过程高效而且可以将检索结果自动按照相关性优先级排序返回,提升检索的体验。
通常当检索的表数据量很大、检索的对象是大文本信息时,需要用Elasticsearch模型替代基于传统数据库查询的方案来进行检索。
SuccBI提供的Elasticsearch模型将Elasticsearch中的索引看做普通的数据库表来进行管理。与其他模型不同的是,Elasticsearch模型不能用于数据加工,但你可以使用它轻松的实现如下功能:
- 创建新的索引、设置字段的分词器并传统数据库表中的数据提取到ES索引中
- 使用第三方系统中已存在ES索引进行查询检索
- 可视化制作的个性化检索页面使用ES中的数据检索
# 创建Elasticsearch模型
提示
- Elasticsearch与传统数据库的库表概念有所不一样,Elasticsearch中的索引(index)的概念对应传统数据库中的表(table),所以后文提到的Elasticsearch索引可以理解为数据库中的表。
- Elasticsearch模型存储在Elasticsearch引擎中,所以在创建前需要先准备好Elasticsearch数据源,并在项目设置中设置好默认的Elasticsearch数据源,以便保存Elasticsearch模型时自动创建Elasticsearch索引。
例如,企业检索中常常需要对【企业名称】和【经营范围】进行全文检索,可以创建Elasticsearch模型,并把企业基本信息表的数据同步到Elasticsearch引擎中,之后基于该模型进行检索。
示例地址:企业基本信息表-ES (opens new window)
# 操作步骤
- 选择数据>新建>更多>Elasticsearch模型,创建新的Elasticsearch模型
- 在数据来源中,点击添加,选择企业基本信息表
- 输入来源标识:企业基本信息
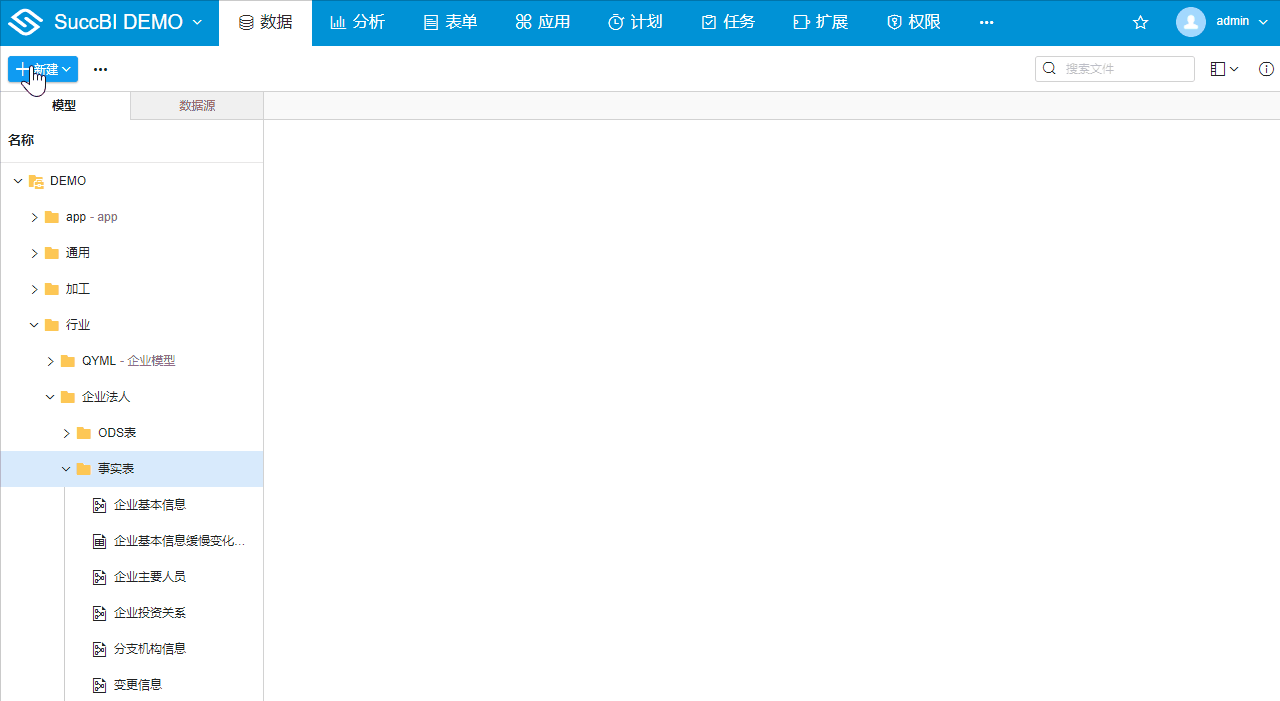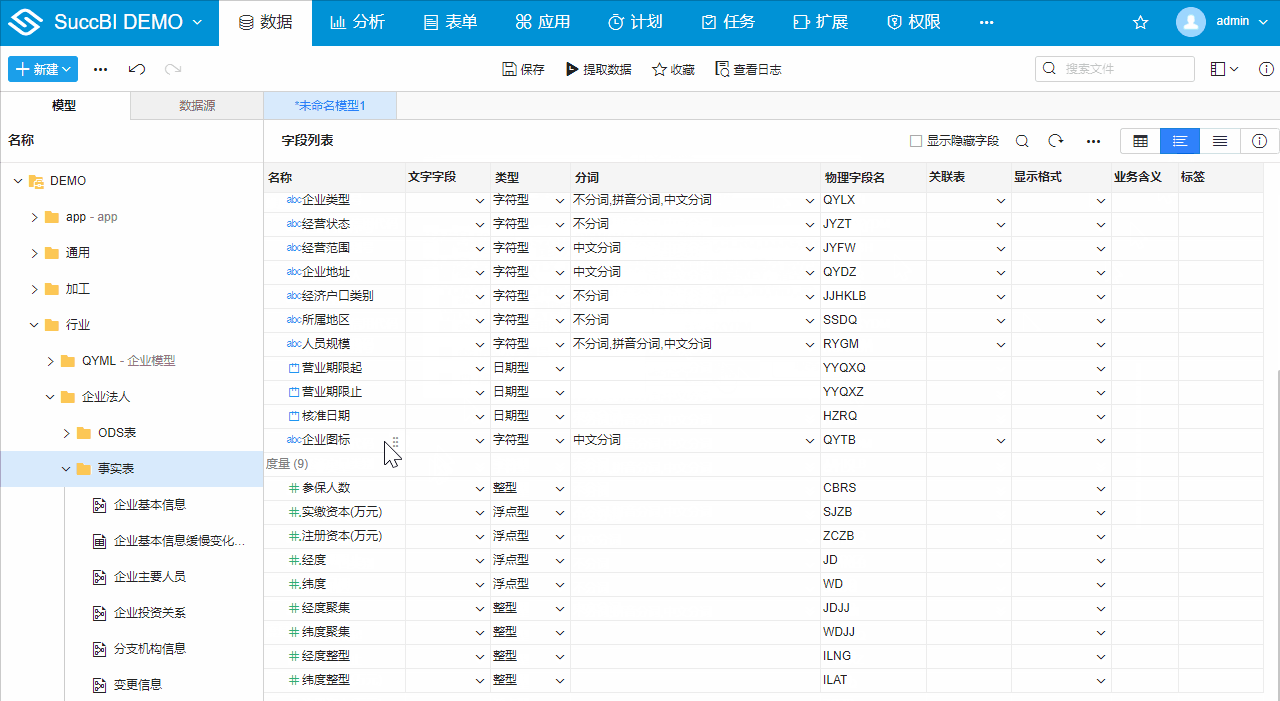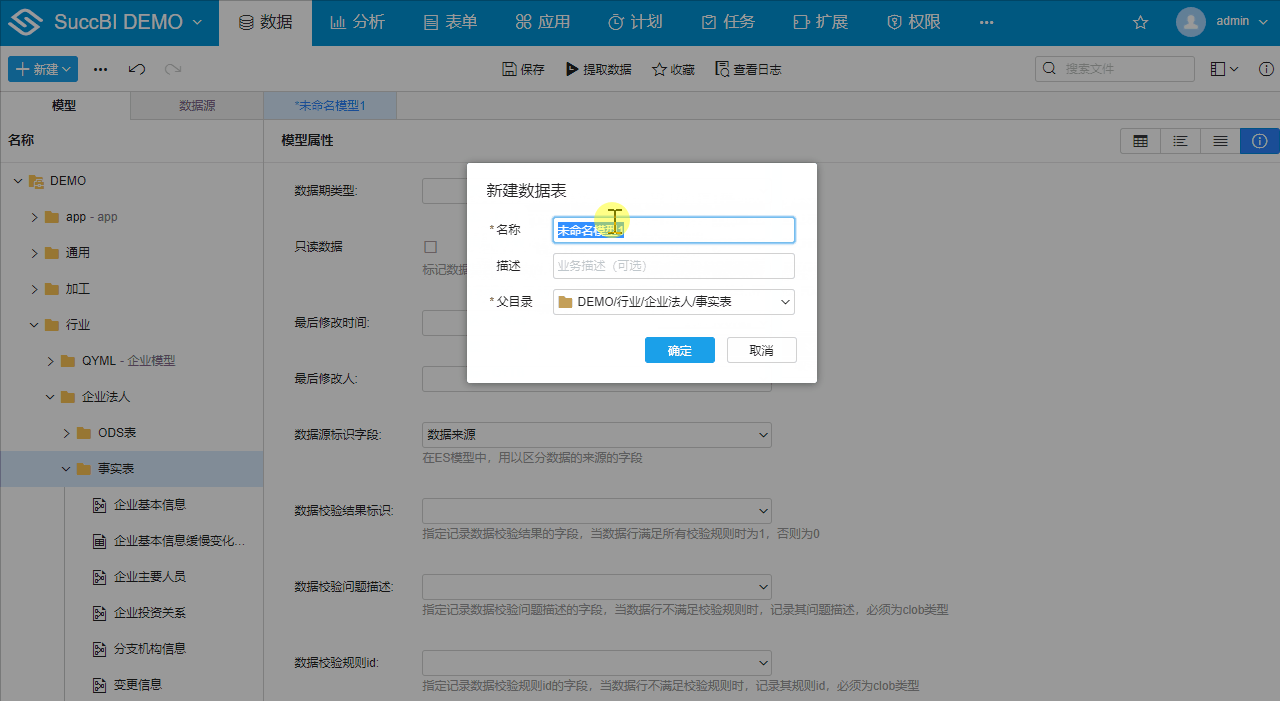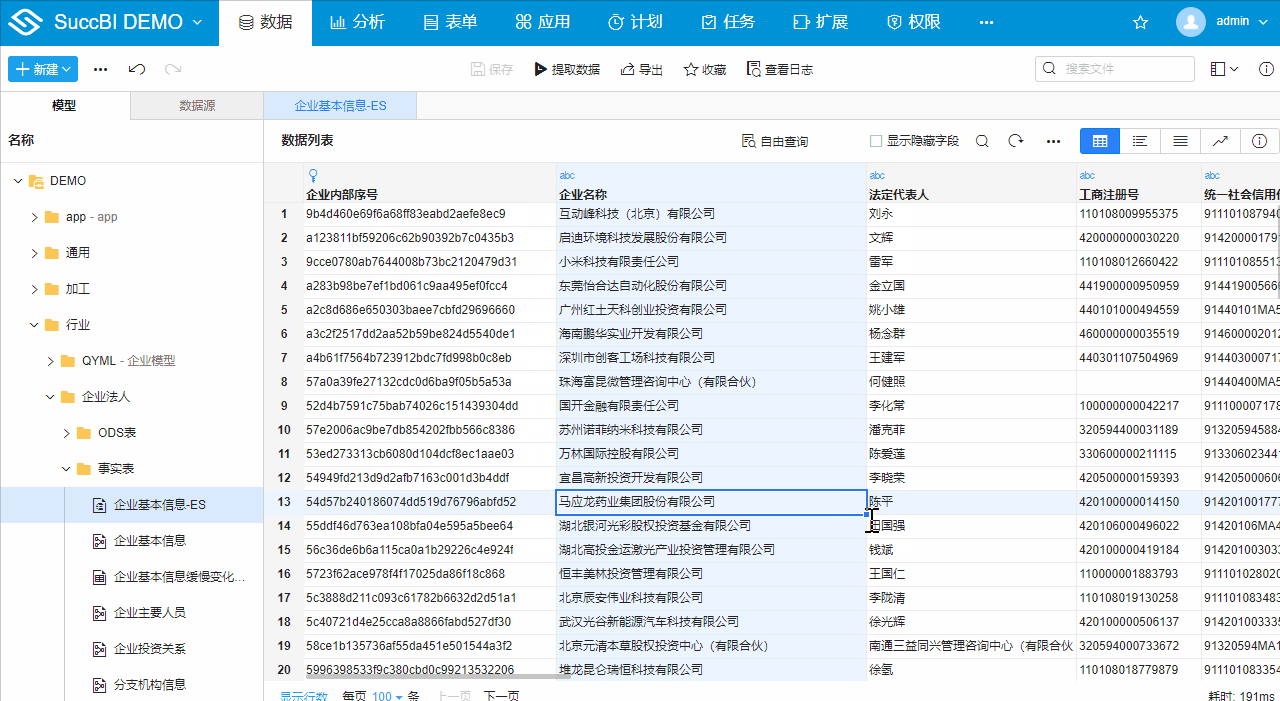
- 点击选择字段,勾选全选,即同步所有字段
- 模型标签页切换至字段列表,并添加字段【数据来源】
- 模型标签页切换至模型属性,添加主键【企业内部序号】,添加数据源标识字段【数据来源】
- 保存模型,点击提取,即可将
企业基本信息表数据全部同步到Elasticsearch中
# 属性介绍
# 数据来源
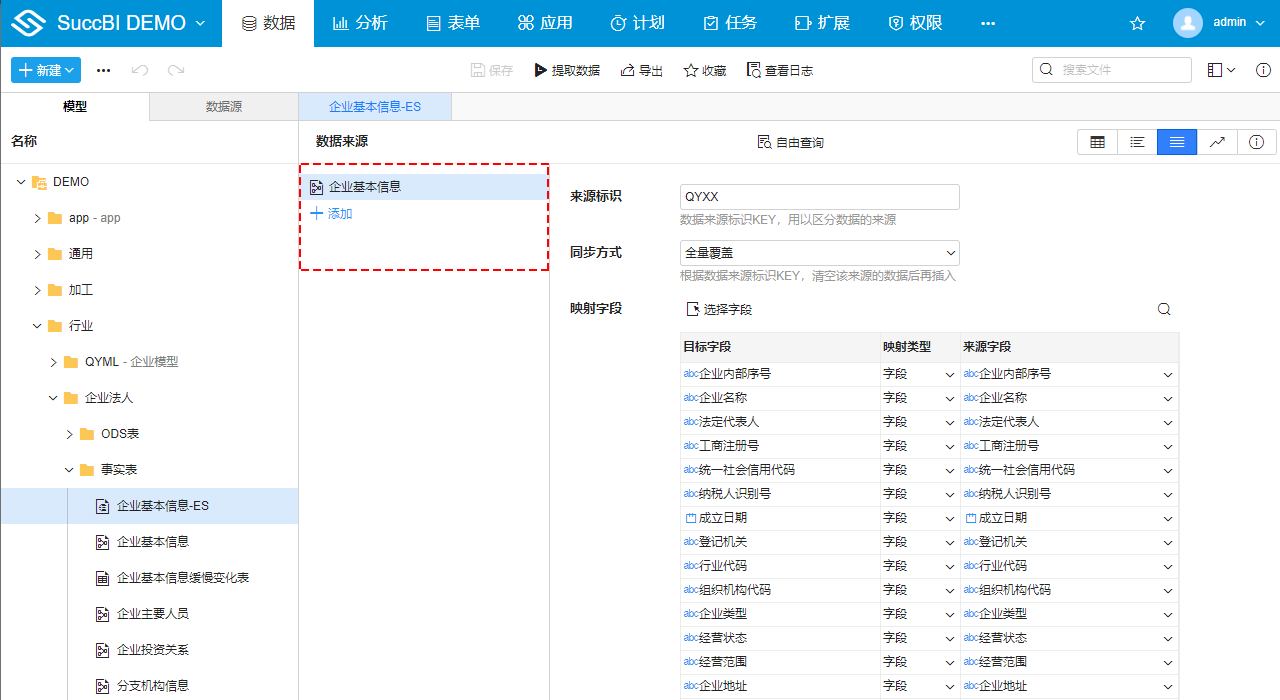
Elasticsearch模型支持添加多个来源模型,设置字段映射关系后,将数据同步到同一个Elasticsearch索引中,方便进行统一的检索,比如社区的全站检索,可以把不同业务模块的业务表(如问答表、博客表、文档表等)同步到一个Elasticsearch索引后进行检索。
# 来源标识
必填,用来区分数据来源。当有多个来源表时,同步到Elasticsearch后,需要根据该标识来区分数据行是来自哪个模型。比如将社区的问答表、博客表、文档表同步到ES时,可以分别设置三个表的来源标识为问答、博客、文档。
# 同步方式
同步方式指将来源数据同步到目标Elasticsearch的方法,类似数据加工的提取方式。支持三种同步方式:
- 全量覆盖
默认的同步方式,先根据当前来源表的来源标识删除目标表中的数据,再插入当前数据来源的数据,适合小数据量的全量更新。
- 清空旧数据并插入新数据
根据设置的清空范围条件以及来源表的来源标识先删除目标表中的旧数据,再插入当前数据来源的数据。常用于能按照固定时间周期增量同步数据的场景。
- 实时
功能暂未开发。
# 映射字段
Elasticsearch模型可以使用两种方式来创建模型的字段:
- 在模型的字段列表标签页手动创建字段
该方式适用于目标表结构明确的情况,先手动定义字段结构,再添加来源数据,并把来源数据的字段与已定义好的字段结构在映射字段列表中一一对应起来。
- 根据来源表的字段自动创建
可以通过选择字段对话框,勾选需要同步到ES的字段,点击确定时系统能自动将这些字段创建为Elasticsearch模型的字段,并生成一一对应的映射列表。
# 数据源标识字段
在ES模型中,用以区分数据的来源的字段,参见模型属性-数据源标识字段
# 分词属性
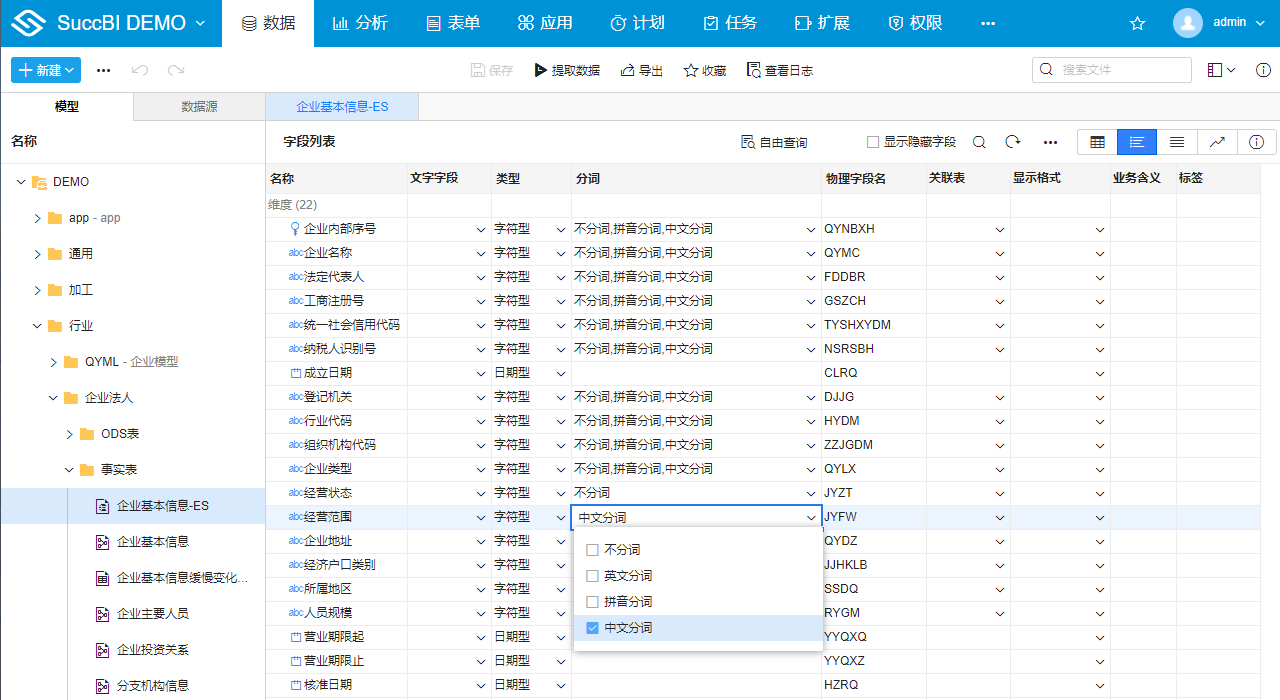
分词是Elasticsearch模型特有的属性,在使用Elasticsearch模型检索时需要对其字符型字段进行简单的分词设置,以便ES能更高效、准确的提供检索服务。
智能映射
ES 检索提供了智能映射的功能,无需手动勾选分词设置,系统会智能推测字段的用途并勾选设置项。需要注意的是,系统智能推测的勾选项通常可以满足正常的应用需求,但并非最优的方案。在大数据量的场景下,建议根据实际需求,仅勾选必要的设置,以节省系统的软硬件资源。
系统自带了四种分词属性设置,需要根据字段的具体应用场景来选择:
提示
Elasticsearch不同的分词对应的分词器的设置详见ES数据源分词器。
- 不分词
不分词是指在Elasticsearch中字段的值不会进行分词拆分,只能使用原值与检索的词项进行匹配。通常不需要进行模糊查询的主键(如企业内部序号)、维键(如登记机关)、编号(统一社会信用代码)等字段选择为不分词。
- 英文分词
英文分词是指将英文文本数据按照英文分词器分词后存储在elasicsearch中进行检索,主要用于英文文本字段的检索,比如英文文章检索、英文的专利检索等场景。
- 拼音分词
拼音分词是指将文本数据按照拼音分词器分词后存储在elasicsearch中进行检索,主要用来进行同音查询和纠错查询,比如查询haitian,能匹配海天;查询无憾,能匹配武汉;查询思各baba,能匹配四个爸爸文化传媒(武汉)有限公司。
- 中文分词
中文分词是指将中文的文本数据按照中文分词器分词后存储在elasicsearch中进行检索,主要用于中文文本字段的检索,比如企业的经营范围、专利的说明书、产品的文档手册。
# Elasticsearch模型处理关联关系
与传统的关系型数据库不同,Elasticsearch属于NoSQL,其不支持传统意义上的关联查询,即不支持两个表通过Join的方式联结在一起进行查询或过滤。但是实际应用中,常常遇到需要关联查询的场景,比如企业信息表关联登记机关维表获取省级登记机关、企业基本信息表关联企业主要人员表过滤查询与某人相关联的企业的基本信息等。
总的来说,需要关联的场景根据关联后数据量是否与主表相同,可以分为两种情况:多对一(或一对一)和一对多(或多对多),针对两种场景,Elasticsearch模型都能通过建模的方法解决。
# 使用字段冗余处理多对一或一对一的关系
多对一通常是事实表与维表的关系,比如企业基本信息表与登记机关维表(企业基本信息表是主表),一对一通常是两个事实表之间以主键关联的关系,比如纳税人信息表和纳税人扩展信息表(纳税人信息表是主表),这两种关系在传统数据库中可以直接通过关联获取副表的属性。在Elasticsearch中需要避免关联,可以通过建模将副表的属性直接冗余到Elasticsearch模型中,实际处理时分为两种场景:
- 设置关联表
如果需要关联的表是事实表维键中设置的关联表,如企业基本信息表的【登记机关】字段设置了关联表登记机关表,系统会自动将维表的所有字段冗余到Elasticsearch模型中,在使用时透明无感知,还是当做普通模型一样去制作应用的页面。
有时候关联维表的字段非常多,使用时用不到,出于性能的考虑,可以通过预连接功能只冗余部分字段到Elasticsearch模型中。
- 使用预加工
当需要关联的表是两个事实表时,通常不会把需要关联的副表当做维表设置为主表维键的关联表,可以通过提前进行一次加工(可以不提取)将需要冗余的字段在加工中提前准备好,再将该加工作为Elasticsearch的来源模型同步到Elasticsearch中。
# 使用Json字段处理一对多或多对多的关系
通常在使用时还会遇到一对多的关系,比如企业基本信息表和企业主要人员表,一个企业可以有多个主要人员,一个自然人又可以在多个企业担任职务。此时如何要查询与某个人相关联的企业基本信息时,传统数据库查询时是企业基本信息表作为主表使用EXISTS进行关联过滤,过滤表达式为:EXISTS SELECT([企业主要人员表].[主要人员ID],[企业主要人员表].[企业内部序号]=[企业基本信息表].[企业内部序号] AND [企业主要人员表].[主要人员代码]='要查询人员的代码')
Elasticsearch模型不能使用关联而是通过创建JSON字段,将企业的多个主要人员的信息存储在企业数据行内部(JSON字段里存储的是多个主要人员信息的json数组,Elasticsearch底层采用嵌套对象 (opens new window)实现)。
# 创建JSON字段
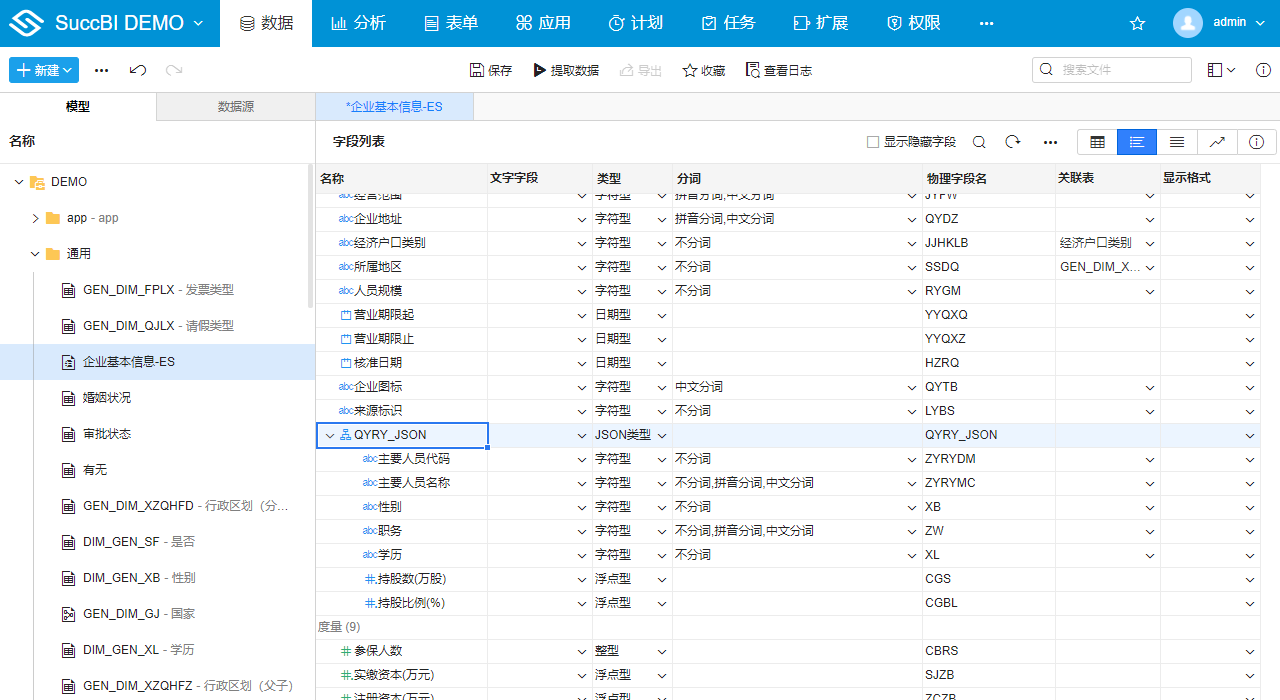
示例地址:主要人员-JSON字段 (opens new window)
操作步骤:
- 右键选择创建JSON字段
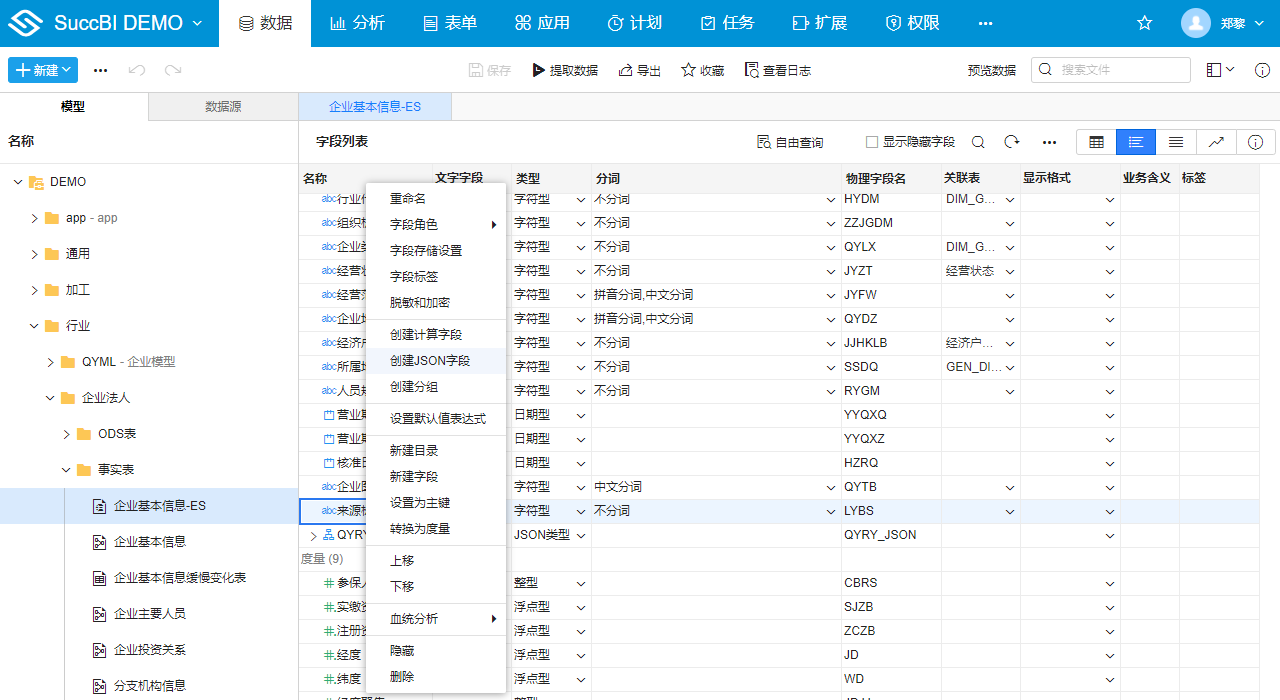
点击后,会弹出JSON字段创建的对话框
- 设置JSON字段
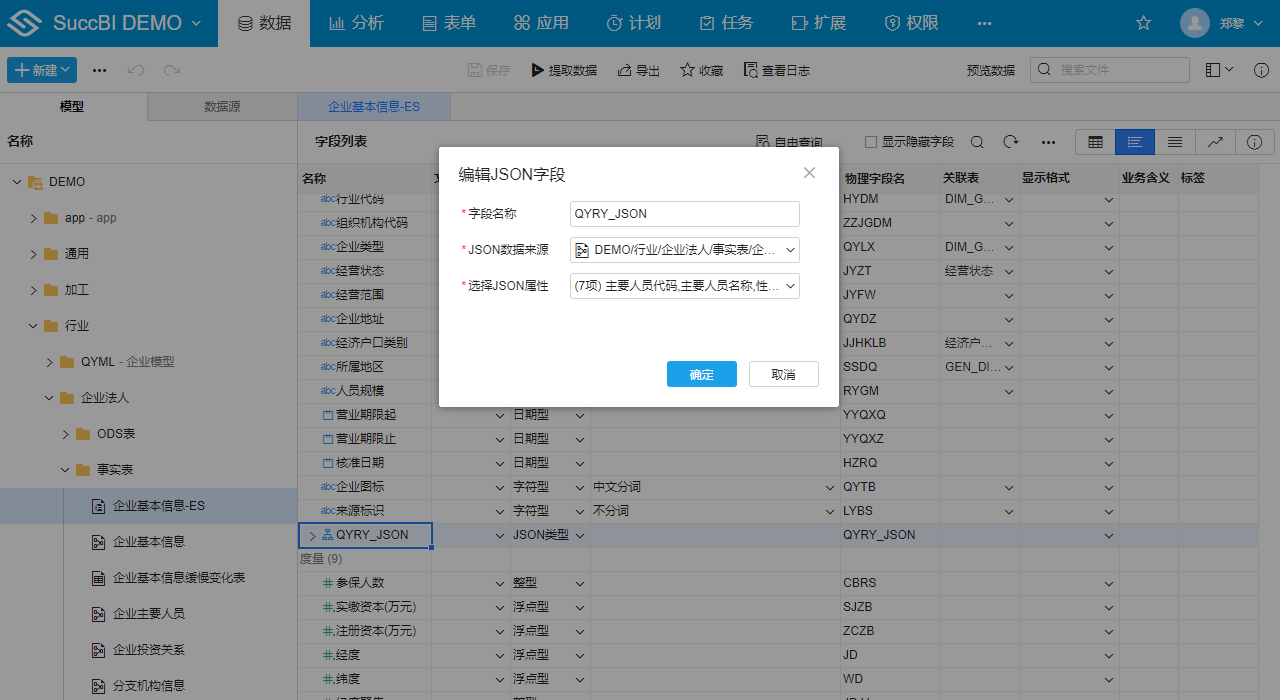
在JSON字段对话框需要设置如下属性:
- 字段名称:JSON字段的名称
- JSON数据来源:需要关联的表,比如上面例子中就是选择:
企业主要人员表 - 选择JSON属性:需要存储在JSON中的来源表的属性,关联的表字段可能非常多,可以只选择必要的字段存储在JSON中
JSON字段在字段列表中可以展开显示,并当做独立的字段设置其字段属性,比如数据类型、分词设置等,在应用时和设置了关联表的维键字段一样,可以展开JSON字段使用其子字段进行过滤和查询,比如上述传统关系数据库的写法表达式在使用Elasticsearch模型时可以直接写为:[企业基本信息].[QYRY_JSON].[主要人员代码]='要查询人员的代码'
# 导入为Elasticsearch模型
上文介绍的主要是将Elasticsearch当做数据仓库数据源,通过手动创建Elasticsearch模型,并添加来源模型,将来源的数据同步到Elasticsearch中进行全文检索的场景,在实际应用中,可能还需要把已存在的Elasticsearch索引导入为Elasticsearch模型,比如一个系统中部署了多个相关项目,多个项目可能都需要用到同一个Elasticsearch索引进行全文检索,但是只会在其中一个项目中进行数据的同步,此时便可以通过导入模型的方式将Elasticsearch中的索引导入为Elasticsearch模型,操作方式与数据表导入模型相同。
需要注意的是,在选择连接方式时,导入Elasticsearch时只支持实时连接(只读模型)和实时连接(读写模式)。
对于Elasticsearch模型来说,两种连接方式的区分是以实时连接(只读模型)方式导入后,是直接使用Elasticsearch索引进行数据的检索查询,同时在模型管理中数据来源标签页会被隐藏;而以实时连接(读写模式)方式导入后,实际上相当于只是设置了一下目标表的名称,还需要在数据来源标签页添加来源模型并提取数据。所以需要导入时,通常都是以实时连接(只读模型)方式导入使用的。